Aerospike enables use of flash storage (SSD, PCIe, NVMe) in parallel on one machine to perform reads at sub-millisecond latencies at very high throughput (100K to 1M) in the presence of a heavy write load. This use of SSD enables enormous vertical scaleup at a 5x lower total cost of ownership (TCO) than pure RAM.
Aerospike implements a hybrid memory architecture wherein the index is purely in-memory (not persisted), and data is stored only on a persistent storage (SSD) and read directly from the disk. Disk I/O is not required to access the index, which enables predictable performance. Such a design is possible because the read latency characteristic of I/O in SSDs is the same, regardless of whether it is random or sequential. For such a model, optimisations described are used to avoid the cost of a device scan to rebuild indexes.
This ability to do random read I/O comes at the cost of a limited number of write cycles on SSDs. In order to avoid creating uneven wear on a single part of the SSD, Aerospike does not perform in-place updates. Instead, it employs a copy-on-write mechanism using large block writes. This wears the SSD down evenly, which, in turn, improves device durability. Aerospike bypasses the Operating System’s file system and instead uses attached flash devices directly as a block device using a custom data layout.
When a record is updated, the old copy of the record is read from the device and the updated copy is written into a write buffer. This buffer is flushed to the storage when completely full.
The unit of read, RBLOCKS, is 128 bytes in size. This increases the addressable space and can accommodate a single storage device of up to 2TB in size. Writes in units of WBLOCK (configurable, usually 1MB) optimize disk life.
Aerospike operates on multiple storage units of this type by striping the data across multiple devices based on a robust hash function; this allows parallel access to the data while avoiding any hot spots.
Note that SSDs can store an order of magnitude more data per node than DRAM. The IOPS supported by devices keep increasing; for instance, NVMe drives can now perform 100K IOPS per drive. Many 20-30 node Aerospike clusters use this setup and run millions of operations/second 24√ó7 with sub-millisecond latency.
For more information please visit https://www.aerospike.com/features/hybrid-memory-architecture/
Converter Sim Hybrid / Kartu sim hybrid Penghubung / Memory Card Penghubung / Sim 2, micro Sd Hybrid Xiaomi Redmi Note 3, pro 4,5 Note 4X, Redmi 3S, 3x, 3 pro, Mi Max, Redmi Pro, infinix , meizu
Hybrid Memory Cube (HMC) is a high-performance computer random-access memory (RAM) interface for through-silicon via (TSV)-based stacked DRAM memory. HMC competes with the incompatible rival interface High Bandwidth Memory (HBM).
Hybrid Memory Cube was co-developed by Samsung Electronics and Micron Technology in 2011,[1] and announced by Micron in September 2011.[2] It promised a 15 times speed improvement over DDR3.[3] The Hybrid Memory Cube Consortium (HMCC) is backed by several major technology companies including Samsung, Micron Technology, Open-Silicon, ARM, HP (since withdrawn), Microsoft (since withdrawn), Altera (acquired by Intel in late 2015), and Xilinx.[4][5] Micron, while continuing to support HMCC, is discontinuing the HMC product [6] in 2018 when it failed to achieve market adoption.
HMC combines through-silicon vias (TSV) and microbumps to connect multiple (currently 4 to 8) dies of memory cell arrays on top of each other.[7] The memory controller is integrated as a separate die.[2]
HMC uses standard DRAM cells but it has more data banks than classic DRAM memory of the same size. The HMC interface is incompatible with current DDRn (DDR2 or DDR3) and competing High Bandwidth Memory implementations.[8]
HMC technology won the Best New Technology award from The Linley Group (publisher of Microprocessor Report magazine) in 2011.[9][10]
The first public specification, HMC 1.0, was published in April 2013.[11] According to it, the HMC uses 16-lane or 8-lane (half size) full-duplex differential serial links, with each lane having 10, 12.5 or 15 Gbit/s SerDes.[12] Each HMC package is named a cube, and they can be chained in a network of up to 8 cubes with cube-to-cube links and some cubes using their links as pass-through links.[13] A typical cube package with 4 links has 896 BGA pins and a size of 31×31×3.8 millimeters.[14]
The typical raw bandwidth of a single 16-lane link with 10 Gbit/s signalling implies a total bandwidth of all 16 lanes of 40 GB/s (20 GB/s transmit and 20 GB/s receive); cubes with 4 and 8 links are planned, though the HMC 1.0 spec limits link speed to 10 Gbit/s in the 8-link case. Therefore, a 4-link cube can reach 240 GB/s memory bandwidth (120 GB/s each direction using 15 Gbit/s SerDes), while an 8-link cube can reach 320 GB/s bandwidth (160 GB/s each direction using 10 Gbit/s SerDes).[15] Effective memory bandwidth utilization varies from 33% to 50% for smallest packets of 32 bytes; and from 45% to 85% for 128 byte packets.[7]
As reported at the HotChips 23 conference in 2011, the first generation of HMC demonstration cubes with four 50 nm DRAM memory dies and one 90 nm logic die with total capacity of 512 MB and size 27×27 mm had power consumption of 11 W and was powered with 1.2 V.[7]
Engineering samples of second generation HMC memory chips were shipped in September 2013 by Micron.[3] Samples of 2 GB HMC (stack of 4 memory dies, each of 4 Gbit) are packed in a 31×31 mm package and have 4 HMC links. Other samples from 2013 have only two HMC links and a smaller package: 16×19.5 mm.[16]
The second version of the HMC specification was published on 18 November 2014 by HMCC.[17] HMC2 offers a variety of SerDes rates ranging from 12.5 Gbit/s to 30 Gbit/s, yielding an aggregate link bandwidth of 480 GB/s (240 GB/s each direction), though promising only a total DRAM bandwidth of 320 GB/sec.[18] A package may have either 2 or 4 links (down from the 4 or 8 in HMC1), and a quarter-width option is added using 4 lanes.
The first processor to use HMCs was the Fujitsu SPARC64 XIfx,[19] which is used in the Fujitsu PRIMEHPC FX100 supercomputer introduced in 2015.
JEDEC's Wide I/O and Wide I/O 2 are seen as the mobile computing counterparts to the desktop/server-oriented HMC in that both involve 3D die stacks.[20]
In August 2018, Micron announced a move away from HMC to pursue competing high-performance memory technologies such as GDDR6 and HBM.[21]
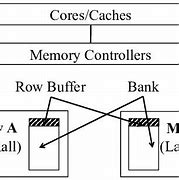
A hybrid memory model, or architecture, is when the index is purely in-memory and not persisted. Data is stored only at persistent storage (SSD) and read directly from the disk. Disk I/O is not required to access the index, which enables predictable performance.
This hybrid memory model is possible because the read latency characteristic of I/O in SSDs is the same. This is regardless of whether it’s random or sequential. For such a model, optimizations described are used to avoid the cost of a device scan to rebuild indexes.
Li J, Lam C. Phase change memory. Science China Information Sciences, 2011, 54(5): 1061–1072
Article Google Scholar
Cai M, Huang H. A survey of operating system support for persistent memory. Frontiers of Computer Science, 2021, 15(4): 154207
Article Google Scholar
Izraelevitz J, Yang J, Zhang L, Kim J, Liu X, Memaripour A, Soh Y J, Wang Z, Xu Y, Dulloor S R, Zhao J, Swanson S. Basic performance measurements of the INTEL optane DC persistent memory module. 2019, arXiv preprint arXiv: 1903.05714
Loh G, Hill M D. Supporting very large DRAM caches with compound-access scheduling and missmap. IEEE Micro, 2012, 32(3): 70–78
Article Google Scholar
Liu H, Chen Y, Liao X, Jin H, He B, Zheng L, Guo R. Hardware/software cooperative caching for hybrid DRAM/NVM memory architectures. In: Proceedings of International Conference on Supercomputing. 2017, 26
Qureshi M K, Srinivasan V, Rivers J A. Scalable high performance main memory system using phase-change memory technology. In: Proceedings of the 36th Annual International Symposium on Computer Architecture. 2009, 24–33
Yoon H, Meza J, Ausavarungnirun R, Harding R A, Mutlu O. Row buffer locality aware caching policies for hybrid memories. In: Proceedings of the 30th IEEE International Conference on Computer Design. 2012, 337–344
Chen C, An J. DRAM write-only-cache for improving lifetime of phase change memory. In: Proceedings of the 59th IEEE International Midwest Symposium on Circuits and Systems. 2016, 1–4
Awad A, Basu A, Blagodurov S, Solihin Y, Loh G H. Avoiding TLB shootdowns through self-invalidating TLB entries. In: Proceedings of the 26th International Conference on Parallel Architectures and Compilation Techniques. 2017, 273–287
Vasilakis E, Papaefstathiou V, Trancoso P, Sourdis I. LLC-guided data migration in hybrid memory systems. In: Proceedings of 2019 IEEE International Parallel and Distributed Processing Symposium. 2019, 932–942
Loh G H, Hill M D. Efficiently enabling conventional block sizes for very large die-stacked DRAM caches. In: Proceedings of the 44th Annual IEEE/ACM International Symposium on Microarchitecture. 2011, 454–464
Jevdjic D, Loh G H, Kaynak C, Falsafi B. Unison cache: a scalable and effective die-stacked DRAM cache. In: Proceedings of the 47th Annual IEEE/ACM International Symposium on Microarchitecture. 2014, 25–37
Hallnor E G, Reinhardt S K. A fully associative software-managed cache design. In: Proceedings of the 27th International Symposium on Computer Architecture. 2000, 107–116
Oskin M, Loh G H. A software-managed approach to die-stacked DRAM. In: Proceedings of 2015 International Conference on Parallel Architecture and Compilation. 2015, 188–200
Wang X, Liu H, Liao X, Chen J, Jin H, Zhang Y, Zheng L, He B, Jiang S. Supporting superpages and lightweight page migration in hybrid memory systems. ACM Transactions on Architecture and Code Optimization, 2019, 16(2): 11
Article Google Scholar
Ryoo J H, John L K, Basu A. A case for granularity aware page migration. In: Proceedings of 2018 International Conference on Supercomputing. 2018, 352–362
Sanchez D, Kozyrakis C. ZSim: fast and accurate microarchitectural simulation of thousand-core systems. ACM SIGARCH Computer Architecture News, 2013, 41(3): 475–486
Article Google Scholar
Poremba M, Xie Y. Nvmain: an architectural-level main memory simulator for emerging non-volatile memories. In: Proceedings of 2012 IEEE Computer Society Annual Symposium on VLSI. 2012, 392–397
Poremba M, Zhang T, Xie Y. Nvmain 2.0: a user-friendly memory simulator to model (non-)volatile memory systems. IEEE Computer Architecture Letters, 2015, 14(2): 140–143
Article Google Scholar
Hao Y, Xiang S, Han G, Zhang J, Ma X, Zhu Z, Guo X, Zhang Y, Han Y, Song Z, Liu Y, Yang L, Zhou H, Shi J, Zhang W, Xu M, Zhao W, Pan B, Huang Y, Liu Q, Cai Y, Zhu J, Ou X, You T, Wu H, Gao B, Zhang Z, Guo G, Chen Y, Liu Y, Chen X, Xue C, Wang X, Zhao L, Zou X, Yan L, Li M. Recent progress of integrated circuits and optoelectronic chips. Science China Information Sciences, 2021, 64(10): 201401
Article Google Scholar
Lu Y, Wu D, He B, Tang X, Xu J, Guo M. Rank-aware dynamic migrations and adaptive demotions for dram power management. IEEE Transactions on Computers, 2016, 65(1): 187–202
Article MathSciNet Google Scholar
Lu Y, He B, Tang X, Guo M. Synergy of dynamic frequency scaling and demotion on DRAM power management: models and optimizations. IEEE Transactions on Computers, 2015, 64(8): 2367–2381
Article MathSciNet Google Scholar
Mittal S, Vetter J S. A survey of software techniques for using nonvolatile memories for storage and main memory systems. IEEE Transactions on Parallel and Distributed Systems, 2016, 27(5): 1537–1550
Article Google Scholar
Zhang J, Guo M, Wu C, Chen Y. Toward multi-programmed workloads with different memory footprints: a self-adaptive last level cache scheduling scheme. Science China Information Sciences, 2018, 61(1): 012105
Article Google Scholar
Gulur N, Mehendale M, Manikantan R, Govindarajan R. Bi-modal DRAM cache: Improving hit rate, hit latency and bandwidth. In: Proceedings of the 47th Annual IEEE/ACM International Symposium on Microarchitecture. 2014, 38–50
Huang C C, Nagarajan V. ATCache: reducing DRAM cache latency via a small SRAM tag cache. In: Proceedings of the 23rd International Conference on Parallel Architecture and Compilation Techniques. 2014, 51–60
Yang D, Liu H, Jin H, Zhang Y. HMvisor: dynamic hybrid memory management for virtual machines. Science China Information Sciences, 2021, 64(9): 192104
Article Google Scholar
Chen T, Liu H, Liao X, Jin H. Resource abstraction and data placement for distributed hybrid memory pool. Frontiers of Computer Science, 2021, 15(3): 153103
Article Google Scholar
Jiang X, Madan N, Zhao L, Upton M, Iyer R, Makineni S, Newell D, Solihin Y, Balasubramonian R. CHOP: adaptive filter-based DRAM caching for CMP server platforms. In: Proceedings of the 16th International Symposium on High-Performance Computer Architecture. 2010, 1–12
Chen P, Yue J, Liao X, Jin H. Trade-off between hit rate and hit latency for optimizing dram cache. IEEE Transactions on Emerging Topics in Computing, 2021, 9(1): 55–64
Luk C K, Cohn R, Muth R, Patil H, Klauser A, Lowney G, Wallace S, Reddi V J, Hazelwood K. Pin: building customized program analysis tools with dynamic instrumentation. ACM SIGPLAN Notices, 2005, 40(6): 190–200
Article Google Scholar
Lee B C, Ipek E, Mutlu O, Burger D. Architecting phase change memory as a scalable DRAM alternative. ACM SIGARCH Computer Architecture News, 2009, 37(3): 2–13
Article Google Scholar
Henning J L. SPEC CPU2006 benchmark descriptions. ACM SIGARCH Computer Architecture News, 2006, 34(4): 1–17
Article Google Scholar
Shun J, Blelloch G E, Fineman J T, Gibbons P B, Kyrola A, Simhadri H V, Tangwongsan K. Brief announcement: the problem based benchmark suite. In: Proceedings of the 24th Annual ACM Symposium on Parallelism in Algorithms and Architectures. 2012, 68–70
Bienia C, Kumar S, Singh J P, Li K. The PARSEC benchmark suite: characterization and architectural implications. In: Proceedings of 2008 International Conference on Parallel Architectures and Compilation Techniques. 2008, 72–81
Zhang Q, Sui X, Hou R, Zhang L. Line-coalescing dram cache. Sustainable Computing: Informatics and Systems, 2021, 29: 100449
Jevdjic D, Volos S, Falsafi B. Die-stacked dram caches for servers: Hit ratio, latency, or bandwidth? Have it all with footprint cache ACM SIGARCH Computer Architecture News, 2013, 41(3): 404–415
Article Google Scholar
Agarwal N, Wenisch T F. Thermostat: application-transparent page management for two-tiered main memory. In: Proceedings of the 22nd International Conference on Architectural Support for Programming Languages and Operating Systems. 2017, 631–644
Aswathy N S, Bhavanasi S, Sarkar A, Kapoor H K. SRS-Mig: selection and run-time scheduling of page migration for improved response time in hybrid PCM-DRAM memories. In: Proceedings of Great Lakes Symposium on VLSI 2022. 2022, 217–222